
Blog posted by Hamima Halim
Structure by Motion-Sickness

It took a lot of light to make this little guy look flat. You may think you are a diva, but you will never never be as much of a diva as 11.4.
The future is now, and its name is computer vision. Computer vision is a branch of computer science involving image processing that addresses the question: if a computer had eyes, what would it do? Its applications include navigation, medical imaging (think CT scans), and manufacturing, among other things. It’s making a splash in archaeology as well, where applications like pattern and object recognition are allowing professionals to analyze and digitally preserve potentially brittle, far-away or endangered material from their own personal machines.
At the BAKOTA project we’re using a technique called photogrammetry to generate 3D models of our graves and vessels without ever having to make our meshes from scratch. This is done by taking photographs of the subject from multiple angles, and, after some processing, plugging it into into Agisoft PhotoscanPro, which detects common points in these images and projects from different angles them to generate a model.

Obama getting the first presidential 3D portrait taken. Picture taken courtesy of the
White House.
Photoscan uses a structure-from-motion algorithm, which is a class of procedures which generate a 3D representation from 2D images. The logic can mimic the processes seeing humans go through to extrapolate a 3D ‘depiction’ in our minds from retinal information. Other professional projects are using the same software or similar, like FlexScan3D.
However, the are many affordable and free options for the amateur photogrammeter to experiment with. Freeware like Autodesk 123D Catch, VisualSFM , and for the more technically inclined, Python’s photogrammetry toolbox are all good to try without shelling out the big bucks.
Outside of archaeology, photogrammetry has been used in commercial portraiture, geological survey, and even in capturing our commander-in-chief.
The Process, and Lessons Learned
We at the BAKOTA Project aren’t the White House, so our available equipment isn’t as upmarket as the Obamas’. Rather than fifty cameras and fifty accompanying lamps, we have seven lamps, one camera and a lazy susan.
First, we place the vessel on the susan and light it such that there are no dramatic shadows. (That’s right, forget the rules about “good” photography here—we want a FLATLY lit subject. Shadows are how you get holes in your model. Do you want holes in your model?)
Then we take a few photos—for simpler pieces, around 50 will do, but we had one vessel that needed over 125 photos to get a decent result. Adjacent photos need to overlap about 75% for a good model so that the program can find enough common features.
The next step is, officially, to put the photos through the PhotoscanPro and mask out the unnecessary details. What we learned, however, was that masking in Photoscan is an unwieldy process which takes lots of effort for little precision. We decided to pre-process the images in Adobe After Effects, where we could mask the photographs in a slightly more efficient manner.

In photography, as in life: focus is
important.
If your backdrop is a) easily distinguishable from your subject, and b) as homogenous as possible, the masking stage will be relatively easy.
However, inconvenient shadows and forms will exist no matter what, and these sorts of spots will a little extra TLC at the masking stage. A failure to mask well will lead to awkward, ambiguous boundaries in the model.
After that, the program handles itself. Sit back for the next 10 hours and watch them bake.
What’s Next?
The next step is to put together these models, along with pit models generated last year, to make a visualization of the graveyard for users to explore.
In the industry, we now have cameras able to take information from the real world as 3D data immediately. Folks at the Max Planck Institute, Stanford and University of Erlangen-Nuremberg have been using these sorts of advances in computer vision to make politicians say fake things on Youtube.
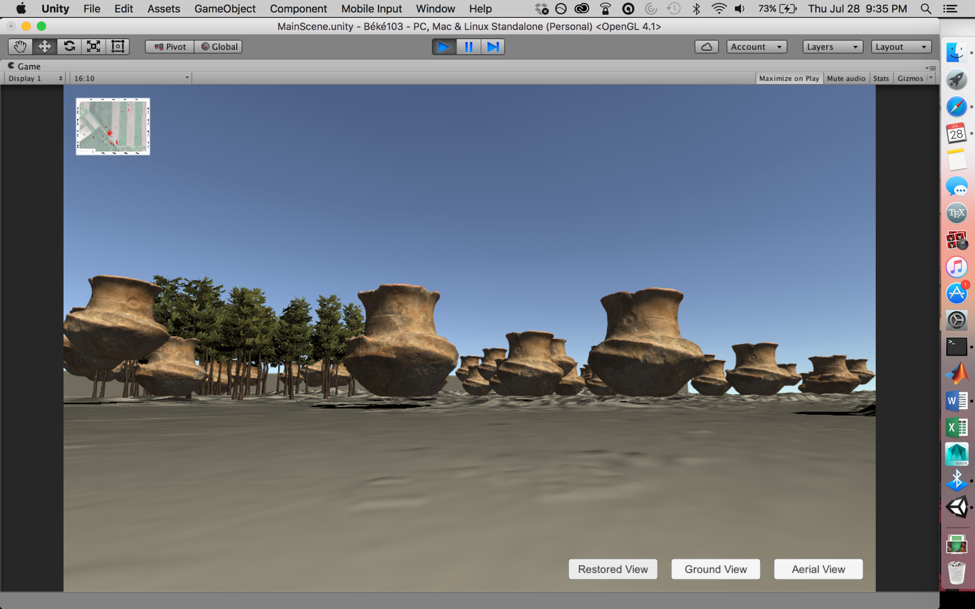
A preliminary test to see if the game could handle around 200 of the vessel meshes at the current face count. The answer was no, so I had to put extra optimizations in place.